개요
유데미 Certified Kubernetes Administrator (CKA) with Practice Tests 강의에서 제공되는 영상과 Vagrantfile을 이용하여 K8S를 구축하였다.
구축한 과정과 트러블 슈팅 내역을 기록하기 위해 글을 작성하였다.
강의에서 제공되는 Vagrantfile을 이용해 virtualBox에서 2 개의 Workernode와 1개의 Control plane을 생성하고 Vagrant ssh를 이용하여 node에 접속한 뒤 환경을 구축하였다.

K8S Cluster
- 버전 1.31.3
- containerd, flannel 사용
- ubuntu 22.4 사용
아래 1번부터 5번까지의 과정은 모든 노드에서 진행해주어야 한다.
1. IP Forwarding 활성화
쿠버네티스의 네트워크 플러그인(CNI, 예: Flannel, Calico 등)은 여러 노드 간 패킷 전달 및 포워딩을 전제로 설계되었기 때문에 사전에 몇 개의 설정이 필요하다.
먼저 IPV4 Forwarding을 활성화 해준다.
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system
sysctl net.ipv4.ip_forward
위 명령어의 결과가 1이면 활성화 된 것이다.

2. br_netfilter 활성화
br_netfilter 모듈이 없으면 브리지 네트워크를 통해 전달되는 패킷이 iptables 규칙을 적용받지 않게 되어 네트워크 정책이 올바르게 작동하지 않을 수 있다.
다음과 같은 명령어로 br_netfilter 모듈을 활성화하고 추가적인 설정을 한다.
sudo modprobe br_netfilter
sudo sysctl net.bridge.bridge-nf-call-iptables=1
sudo sysctl net.bridge.bridge-nf-call-ip6tables=1
echo "net.bridge.bridge-nf-call-iptables=1" | sudo tee -a /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables=1" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
echo "br_netfilter" | sudo tee /etc/modules-load.d/br_netfilter.conf
3. Container Runtime 설치
Kubernetes와 같은 오케스트레이션 시스템에서 컨테이너를 실행하려면, 컨테이너 런타임이 필수적으로 필요하다.
- Docker:
- 가장 널리 사용되는 컨테이너 런타임으로, 컨테이너의 빌드, 배포, 실행을 위한 도구를 제공한다.
- containerd:
- Docker에서 분리된 런타임으로, 컨테이너의 실행, 이미지 관리 등을 담당, Kubernetes와 함께 사용할 수 있다.
- CRI-O:
- Kubernetes와의 호환성을 중시하는 경량화된 컨테이너 런타임으로 Docker의 대신 Kubernetes 클러스터에서 컨테이너를 실행하는 데 사용된다.
이 글에서는 containerd를 Container Runtime으로 사용하였다.
https://docs.docker.com/engine/install/ubuntu/
Ubuntu
Jumpstart your client-side server applications with Docker Engine on Ubuntu. This guide details prerequisites and multiple methods to install Docker Engine on Ubuntu.
docs.docker.com
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# Install containerd
sudo apt-get install containerd.io
systemctl status containerd
위 명령어로 실행 확인 가능하다.

4. Cgroup driver 설정
cgroupfs 드라이버는 kubelet의 기본 cgroup 드라이버이다.
cgroupfs 드라이버가 사용될 때, kubelet과 컨테이너 런타임은 직접적으로 cgroup 파일시스템과 상호작용하여 cgroup들을 설정한다.
sudo su -c "containerd config default > /etc/containerd/config.toml"
sudo vi /etc/containerd/config.toml
vi 에디터를 통해 containerd가 systemd의 cgroup 관리 기능을 사용할 수 있도록 해당 부분을 수정해준다.
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
sudo systemctl restart containerd
그 후에 containerd를 재시작한다.
5. kubeadm, kubelet, kubectl 설치
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
Creating a cluster with kubeadm
Using kubeadm, you can create a minimum viable Kubernetes cluster that conforms to best practices. In fact, you can use kubeadm to set up a cluster that will pass the Kubernetes Conformance tests. kubeadm also supports other cluster lifecycle functions, su
kubernetes.io
sudo apt-get update
# apt-transport-https may be a dummy package; if so, you can skip that package
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
# If the directory `/etc/apt/keyrings` does not exist, it should be created before the curl command, read the note below.
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# This overwrites any existing configuration in /etc/apt/sources.list.d/kubernetes.list
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
sudo systemctl enable --now kubelet
6. kubeadm init
kubernetes에서 pod-network-cidr default 값이 10.244.0.0/16이기에 추가적인 설정을 피하려면 default 값을 사용해준다.
ip address값은 ip add 명령어를 통해 확인할 수 있으며 동일한 과정을 따라왔다면 enp0s8이 해당 값이 되겠다.

kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address={control plane node ip}
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get node, po, ns 어떤 명령으로도 정상 동작을 확인할 수 있다.

kdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
sudo kubeadm join 172.30.1.96:6443 --token udr7l0.hu1o5801ove1jnns \
--discovery-token-ca-cert-hash sha256:d0f0941ac6c28bbf051d552358d8260b7ed1f7c0a2dceb48f2ec80f31799a26e
정상적으로 init이 성공하였다면 위와 같이 결과가 나올텐데 'sudo kubeadm join {controlplane ip}:6443 -token {token}
--discovery-token-ca-cert-hash sha256:{hash} ' 해당 내용을 기록해두었다가 후에 worker node에서 join할 때 사용해야 한다.
7. Network cni 설치
https://github.com/flannel-io/flannel#deploying-flannel-manually
GitHub - flannel-io/flannel: flannel is a network fabric for containers, designed for Kubernetes
flannel is a network fabric for containers, designed for Kubernetes - flannel-io/flannel
github.com
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
다음 명령어를 통해 실행하며 정상적으로 실행이 되었다면 아래와 같은 결과를 얻을 수 있다.

만약 이와 같이 error, crashloopbackoff가 발생한다면 1~4번까지의 단계 중 안한 것이 있는지 체크를 해야 한다.
나 또한 구축하던 도중 아래와 같은 오류를 확인했고 2번 과정을 해주었더니 정상적으로 실행이 되었다.

8. worker node 추가
kubectl 명령어가 길기에 alias를 통해 축약해서 사용하겠다.
alias k='kubectl'
앞서 복사해둔 명령어로 정상적으로 조인이 되었다면 다음과 같이 모든 node들이 ready인 것을 확인할 수가 있다.

만약 Not Ready 상태의 노드가 있다면 해당 노드에서 sudo systemctl restart kubelet을 실행하거나, flannel이 정상 작동중인지 확인해본다.
정상 작동 확인
kubectl run nginx --image=nginx
정상적으로 nginx pod가 worker node 2에 배치가 된 것을 확인할 수 있다.
트러블 슈팅
dns와 flannel 정상 작동하지 않는 경우
control plane에서 각 worker node 위의 뜬 pod 간 통신이 안되고 pod들이 coredns를 통해 dns 시스템에 접근하지 못하는 문제가 발생함
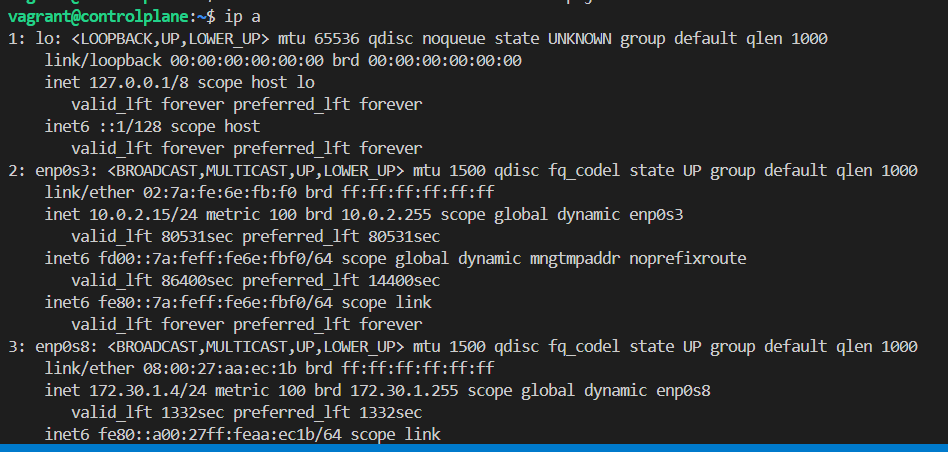
node에 ip가 2개 있었는데 더 작은 ip인 enp0s3가 모두 같아서 생긴 문제라 해석했다.

아래와 같은 명령어로 vi editor로 들어간 다음 --node-ip={구분 가능한 노드 ip}를 추가한다.
sudo vi /var/lib/kubelet/kubeadm-flags.env
그 후 flannel 데이터와 pod를 삭제한 후 다시 생성한다.
'DevOps > Kubernetes' 카테고리의 다른 글
| Kubernetes 외부 ETCD Backup and Restore (0) | 2024.10.27 |
|---|---|
| Kubernetes 내부 ETCD Backup and Restore (0) | 2024.10.26 |
| Kubernetes Cluster Upgrade (0) | 2024.10.24 |
| Kubernetes Drain, Cordon and Uncordon (0) | 2024.10.23 |
| Kubernetes InitContainer (0) | 2024.10.23 |